

- Типы перезагрузок и их причины
- Где в Linux хранится информация
- Просмотр истории перезагрузок
- Анализ системных логов
- Аппаратные причины
- Автоматические перезагрузки
Linux считается стабильной и предсказуемой системой, поэтому внезапная перезагрузка почти всегда вызывает вопросы – а иногда и реальные проблемы. Не понимая причины, такие ситуации сложно контролировать, а еще сложнее – предотвращать.
Разберем основные причины перезагрузки Linux-системы и посмотрим, где искать информацию, которая поможет восстановить картину произошедшего.
Типы перезагрузок и их причины
Перезагрузки Linux можно условно разделить на несколько типов – по тому, как система была перезапущена и что стало триггером:
Плановая перезагрузка
Самый безопасный и предсказуемый тип. Система завершает работу служб, синхронизирует данные на диск и только после этого уходит в перезагрузку. Администратор запускает ее вручную через systemd (reboot, shutdown) или панель управления хостингом.
Следы такой перезагрузки почти всегда есть в логах: фиксируется команда, пользователь и время выполнения. Система успевает корректно закрыть процессы, поэтому последствий для данных, как правило, нет.
Аварийная перезагрузка
Происходит, когда Linux не может продолжать работу в штатном режиме. Чаще всего это связано с критической ошибкой ядра (kernel panic), серьезным сбоем драйвера или проблемами с оборудованием. В таких ситуациях система может перезагрузиться автоматически или зависнуть с последующим ручным рестартом.
Журналы в этом случае могут быть неполными, так как система не успевает записать всю диагностическую информацию.
Перезагрузка из-за аппаратных сбоев
Иногда сама система Linux вообще ни при чем. Перезагрузка может произойти из-за внешних причин – например, резкого отключения электричества, сбоя источника бесперебойного питания (ИБП), перегрева процессора или отказа оперативной памяти. Тогда компьютер мгновенно выключается или перезапускается.
Характерный признак – отсутствие записей о завершении работы системы. Логи обрываются резко, без стандартных сообщений о выключении, а информация о причине может находиться уже на уровне BIOS, BMC или гипервизора.
Перезагрузка со стороны виртуализации
В виртуальной машине перезагрузка может произойти не по вине самой системы, а извне – со стороны гипервизора или облачной платформы. Ее мог перезапустить администратор, могла сработать автоматическая перезагрузка после сбоя или возникла проблема на физическом сервере.
С точки зрения виртуальной машины она происходит внезапно. Логи Linux обрываются, как при отключении питания.
Принудительная перезагрузка
Бывает, что система зависает и не может выключиться нормально. Тогда перезагрузку выполняют принудительно — например, сервер перезагружают через интерфейс управления вроде IPMI и iDRAC или через кнопку reset. Также может сработать watchdog-таймер, и система перезагрузится автоматически.
Где в Linux хранится информация
Linux почти всегда оставляет следы того, что происходило перед перезагрузкой. Проблема в другом: эти следы лежат в разных местах – часть в системном журнале, часть в логах ядра, часть в файлах вроде wtmp, а иногда нужная информация вообще находится за пределами ОС (железо/гипервизор).
Посмотрим подробнее.
Systemd-journald: единый системный журнал
Если система работает на systemd (а это большинство современных дистрибутивов), основная информация хранится в журнале journald. Туда попадают сообщения служб, ядра, логины пользователей, события загрузки и выключения.
Важный момент: журнал бывает постоянным и в памяти. Если настроено хранение только в RAM, то после аварийной перезагрузки часть данных может исчезнуть. Поэтому полезно проверить, включено ли постоянное сохранение журналов.
Логи ядра
Отдельный слой – сообщения ядра: ошибки драйверов, проблемы с дисками, сетевыми интерфейсами, памятью, перегревом и kernel panic. Эти события часто оказываются решающими, потому что именно ядро первым фиксирует аппаратные и низкоуровневые сбои.
Исторически сообщения ядра можно было смотреть в dmesg, а также в файлах /var/log/kern.log или /var/log/messages – зависит от дистрибутива и системы логирования. В systemd большая часть этого дублируется в journald.
Классические текстовые логи в /var/log
Даже если в системе используется journald, многие логи по-прежнему записываются в обычные файлы в папке /var/log. Там можно найти:
- общий системный лог (/var/log/syslog или /var/log/messages);
- лог ядра (/var/log/kern.log);
- лог аутентификации (/var/log/auth.log или /var/log/secure);
- логи отдельных сервисов (например, SSH, веб-серверов, БД).
При расследовании перезагрузок эти файлы помогают восстановить последовательность событий: кто заходил, какие команды выполнялись и что происходило со службами до падения.
Учетные журналы системы
Linux ведет учет загрузок, перезагрузок и входов пользователей в специальных файлах – не как обычные логи, а как записи событий. Два из них особенно полезны:
- /var/log/wtmp – хранит историю всех успешных входов в систему, а также события перезагрузки (reboot) и выключения (shutdown).
- /var/log/btmp – фиксирует неудачные попытки входа (например, по SSH).
По ним удобно понять, была ли перезагрузка запланированной.
Логи падений и дампы: если дело в kernel panic
Если перезагрузка произошла из-за сбоя ядра, помогут специальные отчеты – дампы памяти.
В некоторых системах включен механизм kdump, который при падении ядра сохраняет копию оперативной памяти. Эта копия – как снимок момента аварии. В ней можно увидеть, какой процесс, драйвер или ошибка привели к сбою. Без kdump остаются только короткие сообщения в логах.
Поэтому лучше заранее настроить kdump – так будет проще разобраться при следующей проблеме.
Логи оборудования и гипервизора
Иногда нужной информации нет внутри ОС, потому что событие произошло ниже уровня Linux. Тогда источники другие:
- журналы iDRAC/iLO/BMC (серверные системы);
- события BIOS/UEFI (например, по питанию/температуре);
- логи гипервизора или облачной панели (если это ВМ).
Особенно важно смотреть внешние журналы, если в системе Linux нет записей о завершении работы. Например, логи могут резко обрываться без предупреждений, и часто это означает, что питание было отключено внезапно или перезагрузка вызвана не самой системой, а оборудованием или гипервизором.
Просмотр истории перезагрузок
Чтобы быстро узнать, когда и сколько раз система перезагружалась, есть простая команда – last. Она читает данные из учетного файла wtmp.
Самый простой и наглядный вариант – показать только перезагрузки:

Команда выведет список всех зафиксированных перезапусков системы с датой, временем и длительностью аптайма до следующего события.
Если нужно увидеть более полную картину – включая корректные выключения системы, – используйте расширенный вариант:
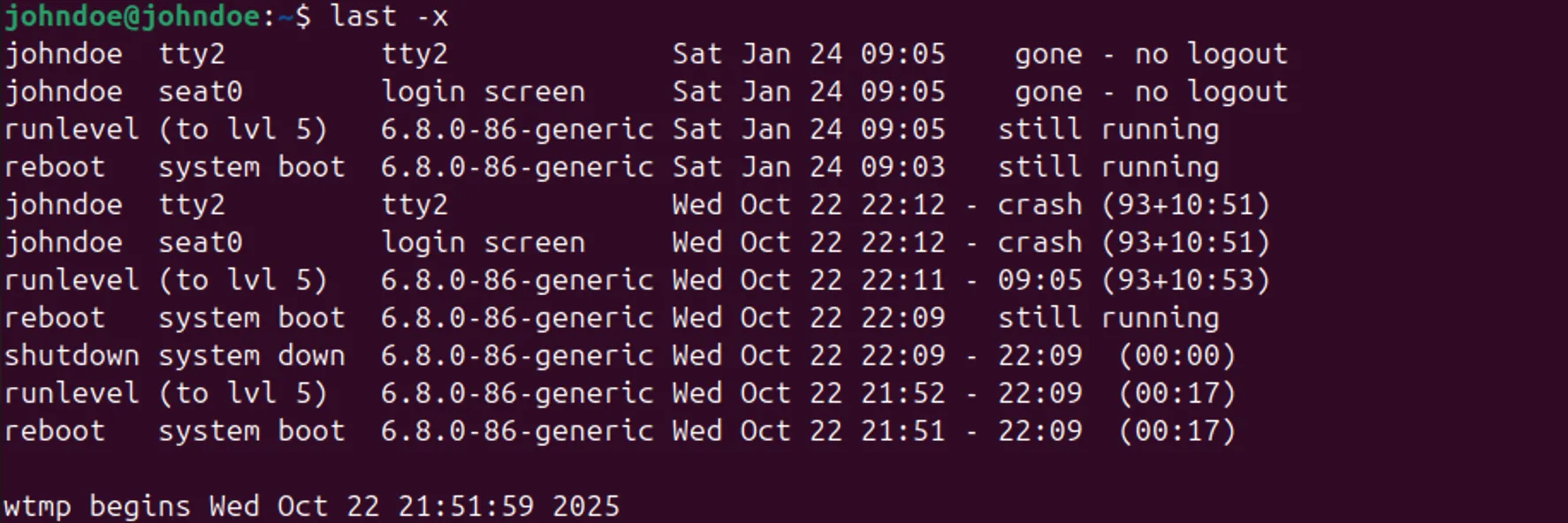
В этом режиме last показывает не только перезагрузки (reboot), но и события shutdown, а также изменения уровня выполнения системы. По этим данным можно понять, была ли перезагрузка штатной или система просто перезагрузилась без корректного завершения работы.
![]() last не объясняет причину перезагрузки – он фиксирует только сам факт события. Зато он отлично подходит для восстановления хронологии.
last не объясняет причину перезагрузки – он фиксирует только сам факт события. Зато он отлично подходит для восстановления хронологии.
Анализ системных логов
Далее важно понять, что происходило перед этим. Главный помощник в этом – системные логи. В них можно найти последовательность событий: какие службы работали, были ли ошибки и кто что делал.
Журнал systemd
В современных дистрибутивах Linux основная часть системных событий попадает в журнал systemd-journald. В нем хранится все, что помогает восстановить картину перед перезагрузкой: сообщения служб, ошибки, предупреждения, действия пользователя, а также события загрузки и завершения работы.
Главный инструмент для работы с журналом – команда journalctl. Без параметров она выводит весь журнал целиком. Чтобы посмотреть, что происходило до последней перезагрузки, выполните:
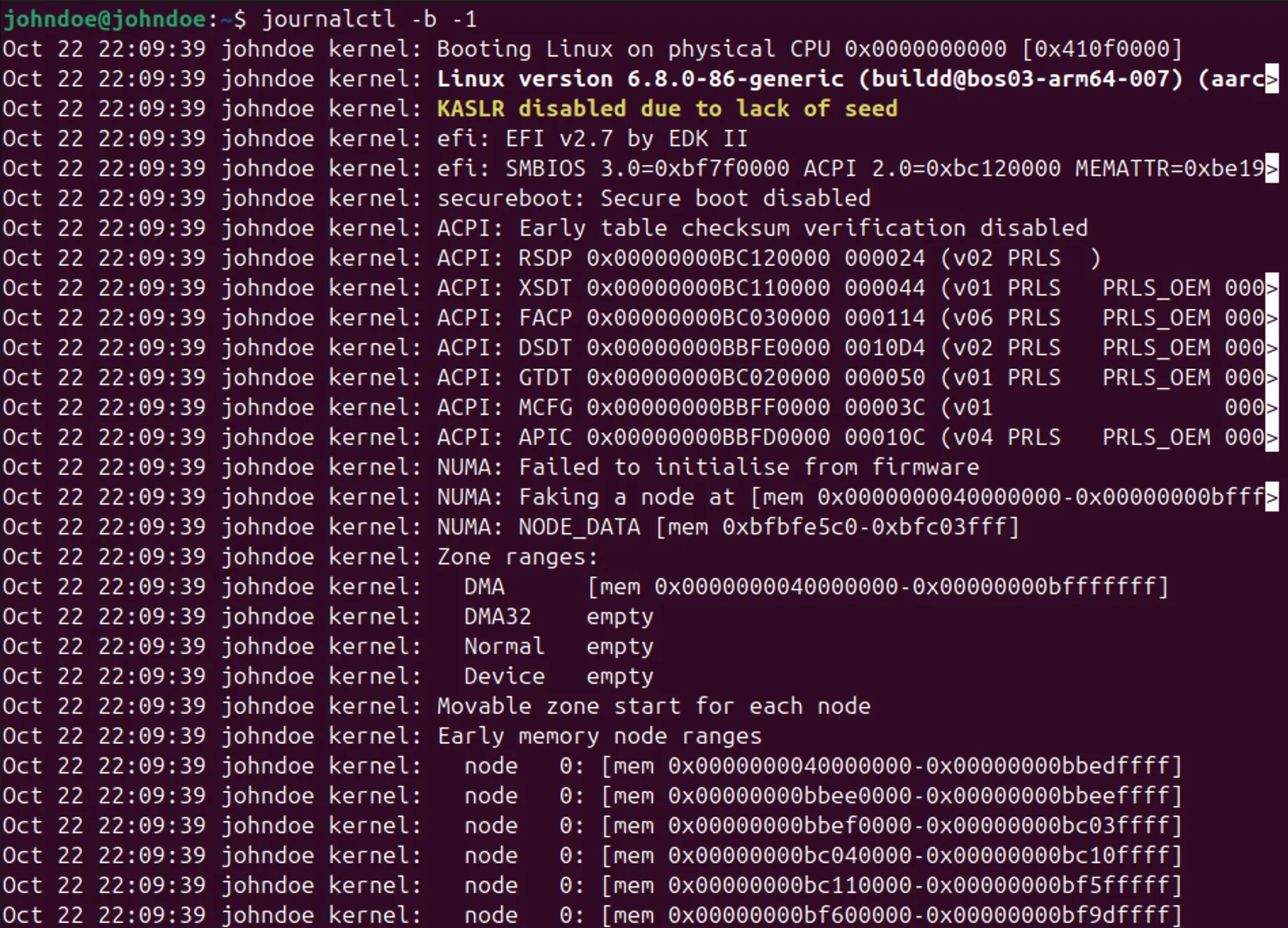
Команда покажет журнал предыдущей загрузки, включая сообщения об ошибках, аварийных завершениях служб и возможных проблемах ядра. Если система была перезагружена корректно, в конце вывода обычно есть записи о штатном завершении работы. Если их нет – это повод задуматься.
При большом количестве перезагрузок удобно сначала посмотреть список всех запусков системы:

Команда выведет нумерованный список загрузок с датами и временем, после чего вы сможете выбрать нужную и проанализировать конкретный журнал.
А чтобы ускорить диагностику, его можно отфильтровать по уровню ошибок:
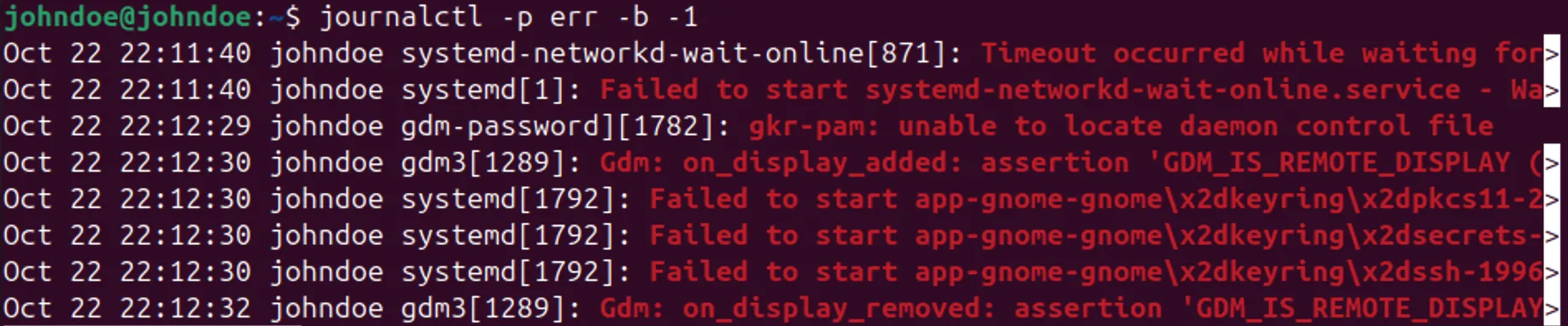
Вывод позволит быстро выделить критические события, которые могли привести к зависанию или перезагрузке системы.
Сообщения ядра
Сообщения от ядра показывают проблемы с оборудованием: дисками, памятью, драйверами, перегревом или критическими сбоями вроде kernel panic.
Посмотреть эти сообщения можно командой:
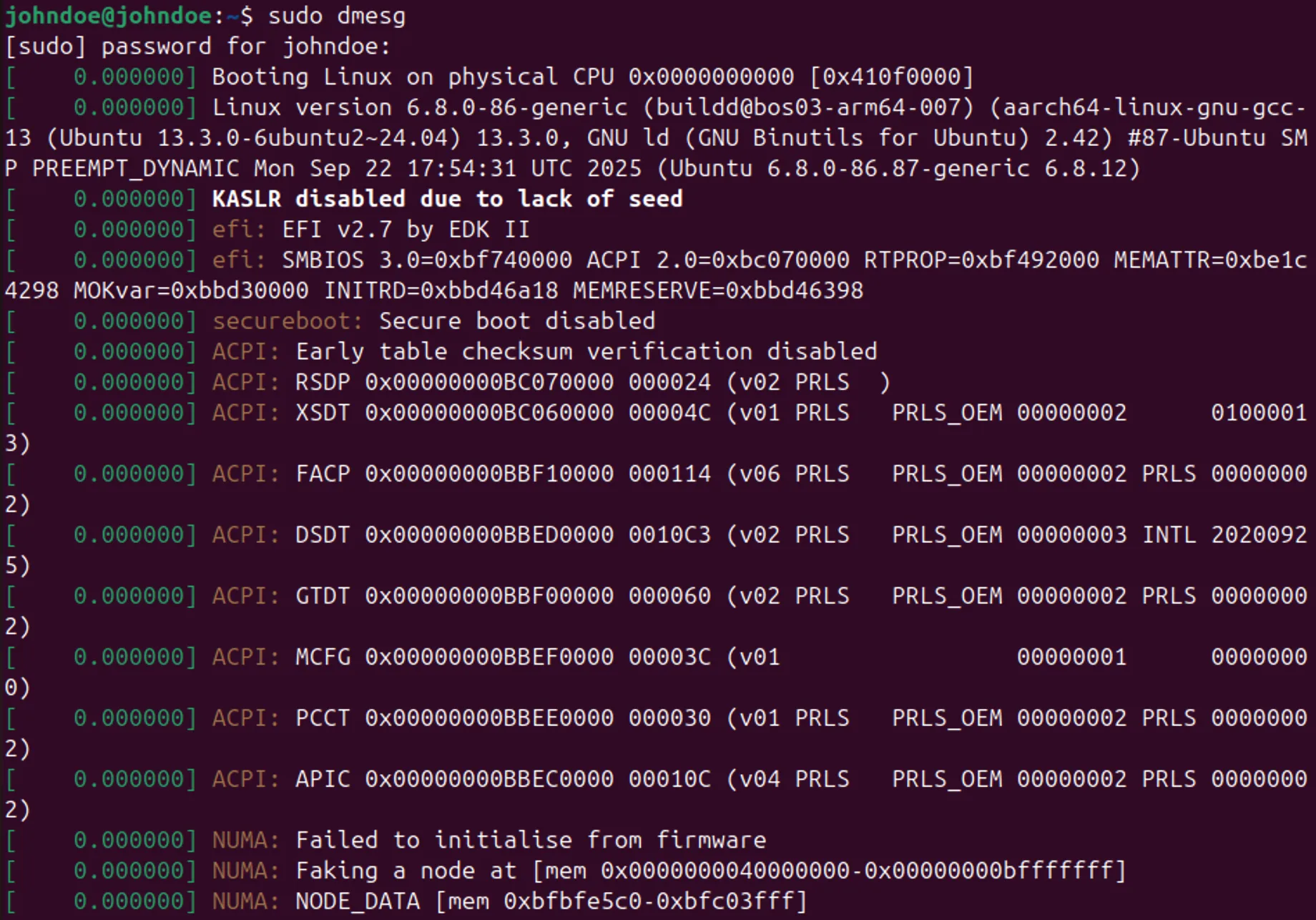
Она выводит записи, которые система сохранила от ядра – ошибки, предупреждения и сбои. Это быстрый способ увидеть серьезные проблемы без просмотра всех логов.
Обращайте внимание на слова:
- error – ошибка,
- fail – сбой,
- panic – крах ядра,
- oom – нехватка памяти,
а также на сообщения о тайм-аутах или перезагрузке устройств.
Но после перезагрузки информация о предыдущем состоянии может быть недоступна, если сообщения ядра не сохранялись в системных журналах
Классические логи в /var/log
Даже при использовании systemd, в Linux часто сохраняются привычные текстовые логи в папке /var/log. Они простые, удобные и остаются после перезагрузки – в отличие от journald, который может хранить логи только в памяти.
Основные файлы:
- syslog (Debian/Ubuntu) или messages (CentOS/RHEL) – основной журнал. В нем видно, что происходило в системе: ошибки, запуск служб, сетевые проблемы и так далее.
- kern.log – лог ядра. Это не полный аналог dmesg, но полезный архив с сообщениями ядра, который может сохраниться даже после перезагрузки.
- auth.log (или secure) показывает, кто входил в систему, использовал sudo и запускал команды.
Файлы в /var/log регулярно архивируются и сжимаются (например, в .1, .2.gz). Поэтому, если перезагрузка была не сегодня, нужные записи могут лежать в архивных файлах.
При анализе логов в /var/log почти всегда используют обычные инструменты фильтрации текста. Самый базовый и полезный – grep. Он позволяет быстро вытащить из логов строки с ошибками и предупреждениями, не просматривая файл целиком.
Чаще всего ищут сообщения с ключевыми словами, которые указывают на проблемы:
grep -i fail /var/log/messages
grep -i panic /var/log/kern.log
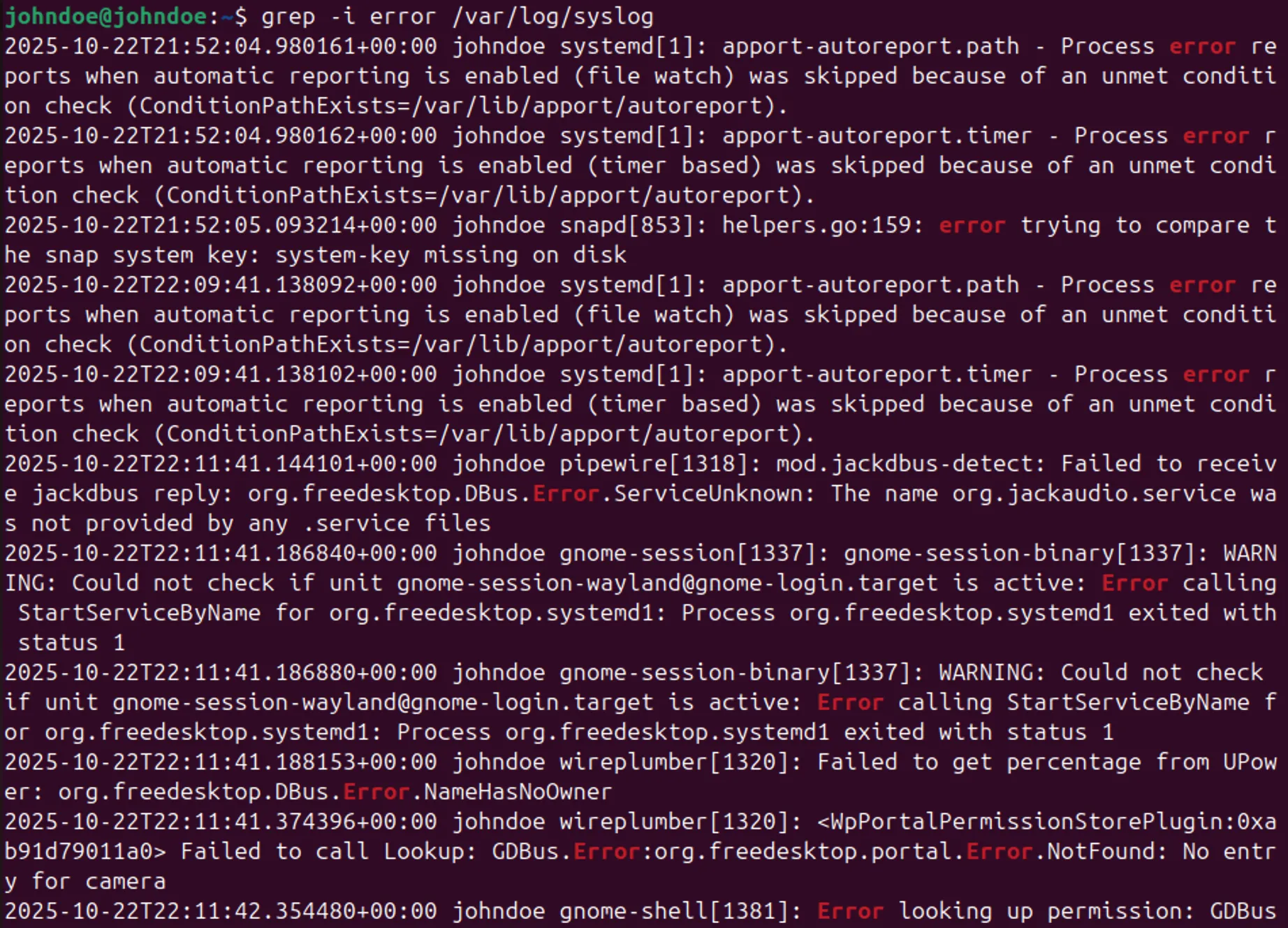
Чтобы посмотреть события перед перезагрузкой, полезно фильтровать лог по времени. Если известно примерное время перезагрузки, можно сузить поиск:
Чтобы просмотреть архивные логи, их не нужно распаковывать. Просто пропишите:
zgrep -i fail /var/log/messages.2.gz
Логи служб и приложений
Перезагрузка системы не всегда связана с ошибками ядра или аппаратными проблемами. Она может произойти из-за сбоя в работе отдельной службы или приложения.
Тогда ключевую информацию содержат не общие системные логи, а журналы самого приложения. Большинство служб ведут собственные записи в подкаталогах /var/log/. Например:
- /var/log/nginx/ – для Nginx,
- /var/log/mysql/ – для MySQL,
- /var/log/postgresql/ – для PostgreSQL,
- /var/log/apache2/ – для Apache.
В этих файлах можно найти ошибки запуска, сообщения о тайм-аутах соединений, утечки памяти и резкий рост числа записей перед перезагрузкой.
Если служба управляется через systemd, ее логи доступны командой:
Она позволяет быстро получить только те записи, которые относятся к нужному сервису.
Аппаратные причины
Причина перезагрузки Linux может быть вне самой операционной системы. Аппаратные сбои могут приводить к внезапной перезагрузке или отключению питания без каких-либо явных записей о корректном завершении работы. В таких случаях логи внутри ОС либо отсутствуют, либо обрываются в один момент.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Автоматические перезагрузки
Не все перезагрузки Linux происходят по инициативе администратора или из-за аварий. В ряде случаев система перезагружается автоматически – по заранее заданным правилам или в ответ на определенные условия.
Основные сценарии автоматической перезагрузки:
- Обновления ядра и системных пакетов. В некоторых дистрибутивах настроена автоматическая установка обновлений, включая ядро. После этого может начаться автоматическая перезагрузка или запускается таймер до перезапуска.
- Настройки systemd. Systemd поддерживает автоматический перезапуск системы при определенных условиях. Например, при срабатывании параметров CrashAction или RebootWatchdogSec система может уйти в перезагрузку после критического сбоя или зависания.
- Watchdog-механизмы. Программный или аппаратный watchdog следит за тем, отвечает ли система. Если она перестает реагировать в течение заданного времени, watchdog инициирует перезагрузку.
- OOM Killer и критическая нехватка памяти. При сильном дефиците оперативной памяти ядро завершает процессы, но в крайних случаях это может привести к нестабильности и последующей перезагрузке.
- Планировщики заданий и скрипты. Перезагрузка может быть задана через cron, systemd-таймеры или пользовательские скрипты.
- Политики виртуализации и облака. В виртуальной среде автоматическая перезагрузка может выполняться со стороны хоста – например, при сбое физического сервера или миграции ВМ.
Автоматические перезагрузки, в отличие от аварийных, почти всегда отражаются в логах.
Заключение
В этой статье мы рассмотрели разные причины перезагрузки Linux-системы и показали, что за внешне одинаковым событием могут скрываться совершенно разные сценарии. Перезагрузка может быть результатом запланированных действий, автоматических механизмов восстановления, сбоев служб и приложений, ошибок ядра или аппаратных проблем.
Ключ к стабильности – действовать по порядку:
- Сначала узнайте, когда и сколько раз система перезагружалась – команда last поможет с этим.
- Затем изучите, что происходило перед этим: проверьте логи – syslog, kern.log, auth.log и journalctl.
- Далее выясните, не была ли перезагрузка инициирована автоматически – например, обновлениями, watchdog или таймерами systemd.
- И только если не нашли причину – переходите к анализу оборудования и внешних систем: BMC, iDRAC, гипервизор или облачная платформа.
Так вы сэкономите себе время и быстрее найдете причину перезагрузки.